fastText
FastText is an open-source, free, lightweight library that allows users to learn text/word representations and text classifiers.
The major benefits of using fastText are that it works on standard, generic hardware and the models can later be reduced in size to even fit on mobile devices.
Introduction
Most of the techniques represent each word of the vocabulary with a distinct vector i.e. without a shared parameter between words. In other words, they ignore the internal structure of words which might affect the learning of languages rich in morphology.
Thus, Enriching Word Vectors with Subword Information proposes an alternative approach where they learn representations for character n-grams and represent words as the sum of the n-gram vectors.
Experimental setup
Subword model
The proposed model sisg (Subword Information Skip Gram) is based on the continuous skipgram model introduced by Mikolov et al. (2013b).
Since the base skipgram model ignores the internal structure of words by using a distinct word representation for each word, sisg proposes a different scoring function s, in order to take into account the internal structure information.
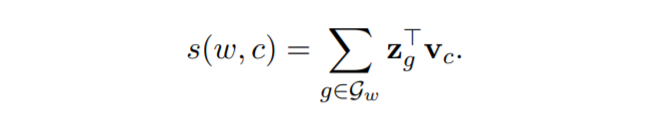
where each word w is represented as a bag of character n-gram, Gw belongs to the set { 1, …, G } of the n-grams of size G. Each n-gram g is associated to a vector represention zgT.
Now, for example, the word where with n=3 will be represented by the character n-grams as <wh, whe, her, ere, re>.
and the special sequence <where>. Here < and > are added as special boundary symbols to distinguish prefixes and suffixes from other characters sequences.
Optimization
The optimization problem is solved by using stochastic gradient descent on the negative log-likelihood function. The optimization is being carried out in parallel where all threads share parameters and update vectors in an asynchronous manner.
Implementation details
Coming to implementation details, sisg has word vectors of dimension 300 where 5 negatives are sampled at random for each positive example. The context window of size c lies between 1 and 5. The step size is set to 0.05 since this is the default value set in the word2vec package and works well for sisg model too.
Also, while building the word dictionary, only those words were kept which appeared at least 5 times in the training set.
Dataset
The sisg model was trained on Wikipedia data which consists of nine languages. The Wikipedia data was pre-processed using a perl script. All the datasets are shuffled and used to train the model over 5 passes.
Now because of the simplicity, the sisg model trains fast and does not require heavy preprocessing or supervision.
Text classification with fastText
Text classification is a core problem to many applications and the fastText tool helps us easily solve this problem.
Installation
Download and unzip the most recent fastText release:
$ wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
$ unzip v0.9.2.zip
Move to the fastText directory and install as follows:
$ cd fastText-0.9.2
# to install using the command-line tool
$ make
# to install via python bindings (we select this approach)
$ pip install .
We check the installation by importing fastText in a Python console:
>>> import fasttext
>>> help(fasttext.FastText)
Help on module fasttext.FastText in fasttext:
NAME
fasttext.FastText
DESCRIPTION
# Copyright (c) 2017-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
FUNCTIONS
load_model(path)
Load a model given a filepath and return a model object.
read_args(arg_list, arg_dict, arg_names, default_values)
tokenize(text)
Given a string of text, tokenize it and return a list of tokens
train_supervised(*kargs, **kwargs)
Train a supervised model and return a model object.
input must be a filepath. The input text does not need to be tokenized
as per the tokenize function, but it must be preprocessed and encoded
as UTF-8. You might want to consult standard preprocessing scripts such
as tokenizer.perl mentioned here: http://www.statmt.org/wmt07/baseline.html
The input file must must contain at least one label per line. For an
example consult the example datasets which are part of the fastText
repository such as the dataset pulled by classification-example.sh.
train_unsupervised(*kargs, **kwargs)
Train an unsupervised model and return a model object.
input must be a filepath. The input text does not need to be tokenized
as per the tokenize function, but it must be preprocessed and encoded
as UTF-8. You might want to consult standard preprocessing scripts such
as tokenizer.perl mentioned here: http://www.statmt.org/wmt07/baseline.html
The input field must not contain any labels or use the specified label prefix
unless it is ok for those words to be ignored. For an example consult the
dataset pulled by the example script word-vector-example.sh, which is
part of the fastText repository.
Dataset
Let’s download example questions from the Stackexchange:
$ wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
Before training a text classifier we need to split the dataset into training and validation sets. We use wc command to check the number of lines in the dataset:
$ wc cooking.stackexchange.txt
15404 169582 1401900 cooking.stackexchange.txt
The dataset contains 15404 lines i.e. 15404 examples which we split into a training set of 12404 examples and a validation set of 3000 examples:
$ head -n 12404 cooking.stackexchange.txt > cooking.train
$ tail -n 3000 cooking.stackexchange.txt > cooking.valid
Train
To train the text classifier we import fastText and then use the train_supervised method by providing the training set as an input parameter.
>>> import fasttext
>>> model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 8974
Number of labels: 735
Progress: 100.0% words/sec/thread: 77120 lr: 0.000000 avg.loss: 9.961853 ETA: 0h 0m 0s
Save
We save the model with save_model so that we can load it later with load_model function:
>>> model.save_model("model_cooking.bin")
Test
We can test the model as follows:
>>> model.predict("Which baking dish is best to bake a banana bread ?")
(('__label__baking',), array([0.21342881]))
The predict method predicts baking tag for the given text input. Let’s look at another example:
>>> model.predict("Why not put knives in the dishwasher?")
(('__label__food-safety',), array([0.09138963]))
The label predicted in this case is food-safety which is not relevant for the given input. To get a better understanding, let’s test the model on the validation set:
>>> model.test("cooking.test")
(3000, 0.172, 0.07438373936860314)
The output contains the number of samples (3000), the precision at one (0.172), and the recall at one (0.074).
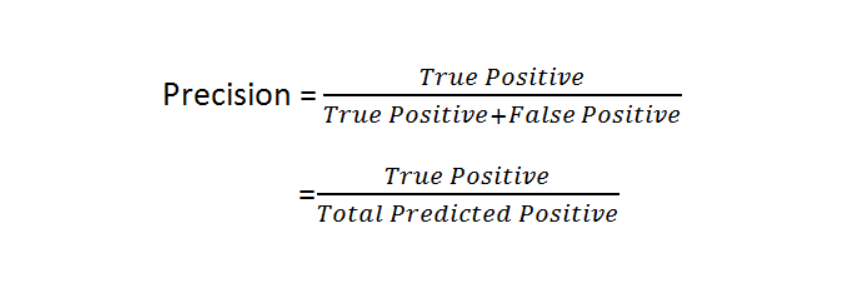
What is precision?
Precision is a measure of how precise or accurate the model is out of those predicted positive, how many of them are actually positive.
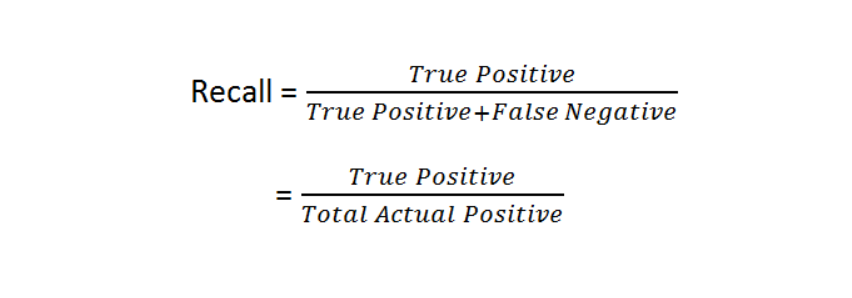
What is recall?
Recall is a measure that calculates how many of the Actual Positives of the model are True Positives.
We can also compute the precision and recall at k (here we use k=5) as follows:
>>> model.test("cooking.test", k=5)
(3000, 0.07286666666666666, 0.1575609052904714)
Optimization
We can optimize and improve the performance of the model by performing various steps given below
Preprocessing the dataset
The raw dataset usually contains elements like uppercase letters or punctuations which are not required for training and might/might not affect the model’s performance. Thus, we can normalize the dataset by using command line tools such as sed and tr:
$ cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt
$ head -n 12404 cooking.preprocessed.txt > cooking.train
$ tail -n 3000 cooking.preprocessed.txt > cooking.valid
Now, we retrain our model on the preprocessed dataset:
>>> model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 46336 lr: 0.000000 avg.loss: 10.019582 ETA: 0h 0m 0s
>>> model.test("cooking.test")
(3000, 0.17466666666666666, 0.07553697563788381)
We can observe a slight improvement in the results which can be significant in other cases.
Tweaking number of epochs and learning rate
fastText sees each training example only 5 times (epochs=5) by default which may be pretty small depending on the size of the dataset. We can change this by using the epoch option while training.
Also, the learning rate of the model corresponds to how much the model changes after processing each example and we can tweak it by using the lr option.
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25)
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 60929 lr: 0.000000 avg.loss: 4.399605 ETA: 0h 0m 0s
>>> model.test("cooking.test")
(3000, 0.585, 0.25299120657344676)
We observe drastic changes in the output results and thus, it is evident that experimenting with hyperparameters such as learning rate and epochs can significantly improve a model’s performance.
n-grams
Currently, we use unigrams for training the model which generally does not help much. Instead, we can use bigrams which might cover prefixes or suffixes properly. In bigrams, we split a sentence or corpus of text into 2 tokens or words, unlike unigrams.
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2)
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 66974 lr: 0.000000 avg.loss: 3.152711 ETA: 0h 0m 0s
>>> model.test("cooking.test")
(3000, 0.6083333333333333, 0.2630820239296526)
The results have further improved with just a single easy step.
Hierarchical Softmax
Finally, we replace the regular softmax function with a hierarchical softmax function for loss since it helps training models on large datasets faster.
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='hs')Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 899564 lr: 0.000000 avg.loss: 2.271247 ETA: 0h 0m 0s
Here, bucket is used to define the bucket size and dim is the dimension of the word vectors.
Autotune
We observed that finding the best hyperparameters is crucial for building efficient models but doing it manually is difficult. This is where fastText’s autotune feature comes to help.
FastText’s autotune feature allows you to automatically perform hyperparameter optimization for the model by providing a validation file with the autottuneValidationFile parameter.
>>> model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid')
Progress: 100.0% Trials: 12 Best score: 0.335514 ETA: 0h 0m 0s
Training again with best arguments
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 66732 lr: 0.000000 avg.loss: 4.540132 ETA: 0h 0m 0s
>>> model.test("cooking.test")
(3000, 0.5583333333333333, 0.24145884388064004)
We get the best F1-score in the output after a default duration of 5 minutes which can be changed by setting the autotuneDuration parameter.
What is F1-score?
F1-score is a function of Precision and Recall as shown below. F1-score is an important measure that is required to seek a proper balance between Precision and Recall.